Dans nos précédents articles, nous avons vu les phases de Conception et de Préparation d’un exercice de gestion de crise cyber en suivant le guide de l’ANSSI et du CCA. Ici nous traitons du déroulement de l’exercice et du retour d’expérience à formaliser.

Dans cet article nous partageons avec vous nos récents travaux sur les offres VMware de certains Cloud Publics (Microsoft , Google , Amazon et Oracle ) et apportons quelques éléments comparatifs tant sur les opportunités économiques (vs du IaaS classique) que sur les modalités de déploiement et de gestion de telles solutions.
Sommaire
- Introduction
- Les solutions VMware dans le cloud public
- Un modèle de responsabilité partagé avec des engagements de service (SLA)
- Topologie de cluster VMware et engagement de service
- Les offres techniques
- Les meilleures pratiques pour l’exécution de workloads VMware sur le cloud public
- Critères de sélection d’une solution VMware dans le cloud public
- Conclusion
Introduction
VMware est une solution que l’on ne présente plus. La société a une place de leader sur le marché de la virtualisation depuis plus de 20 ans.
20 ans plus tard, le catalogue de produits VMware ne cesse de s’étendre pour virtualiser de plus en plus d’assets du datacenter et faciliter la vie de la DSI avec le Software Defined Datacenter (SDDC) : virtualisation du réseau, stockage, sécurité, centre de données, poste de travail, multiclouds, etc.
Les promesses de consolidation, d’économie, de standardisation, d’agilité et d’évolutivité sont nombreuses pour les entreprises.
Quasiment devenu un standard pour une large majorité des DSI, nous comparerons les avantages et inconvénients des offres actuellement sur le marché du Cloud Public concernant les briques principales permettant à VMware de fonctionner : ESXi et vSphere.
Là encore, les promesses des cloud providers sont nombreuses :
- Provisionnement automatique du cluster VMware en quelques heures,
- Disponibilité dans toutes les régions du monde,
- Maintien en condition opérationnel des nœuds physiques,
- Gestion du cycle de vie des logiciels VMware,
- Souscription facilitée : licence VMware incluses, modèle à la demande ou avec un engagement sur 1 ou 3 ans,
- Interfaces avec des services natifs du cloud provider,
- Intégration de VMware dans la console du cloud provider,
- Migration des workloads facilitée avec VMware HCX, à chaud et sans changer d’adresse IP.
Et pour les DSI ? quels avantages ?
- Un modèle 100% OPEX et l’absence d’investissement lourd,
- Un move to cloud en douceur, sans remettre en cause tout l’écosystème technique,
- Un gain de temps considérable sur le déploiement de l’infrastructure,
- La capitalisation sur des compétences déjà acquises sur VMware,
- Une infrastructure dédiée avec un haut niveau de performance (full flash),
- Une réduction des dépenses par rapport à une infrastructure on-prem ou des services en cloud native,
- Une agilité dans le dimensionnement de cette infrastructure (ajout/retrait de nœud),
- Reprendre la maîtrise sur ses machines VMware via vSphere (en comparaison des offres IaaS natives des Cloud Providers et l’absence de mode console),
- Un allégement de la charge de travail et des compétences pour le maintien en condition opérationnel de VMware,
- L’assurance d’avoir une infrastructure à jour pour se prémunir des dernières failles de sécurité,
- Une mise en œuvre rapide/facilitée d’un plan de reprise d’activité informatique,
- Le déploiement rapide et facilité d’une nouvelle infrastructure VMware pour remplacer un datacenter,
- Le déploiement d’environnements de travail temporaire.
Même si toutes les offres se basent sur les technologies VMware fondamentales, l’intégration des services VMware est différente d’une cloud provider à l’autre et il n’est pas simple de s’y retrouver lorsque qu’on souhaite comparer les solutions.
Cet article a été rédigé sur la base de mon expérience chez des opérateurs de cloud privé et public (CSP), de mission pour des clients finaux, d’échange avec des administrateurs infrastructure, d’échange avec des partenaires ainsi qu’avec VMware. Les informations utilisées sont disponibles auprès des opérateurs en question.
Nous espérons que cette synthèse comparative pourra vous guider dans votre réflexion.
Les solutions VMware dans le cloud public
Les premières offres et solutions VMware sur le cloud public existent pour certaines depuis 2018. Je me rappelle de la première présentation de VMware sur Amazon Web Service à laquelle j’ai pu assister à l’occasion de Re:Invent. A l’époque, je n’avais pas compris l’intérêt de cette offre pour AWS, je pensais qu’ils se tiraient une balle dans le pied en sortant VMC on AWS. Migrer des machines au format VMware sur AWS ? cela revient à ne pas consommer de service managé ?
6 ans plus tard, tous les providers de cloud proposent une implémentation de VMware dans leur catalogue :
- Amazon : VMware Cloud on AWS (VMC)
- Microsoft : Azure VMware Solution (AVS)
- Google : Google Cloud VMware Engine (GCVE)
- Oracle : Oracle Cloud VMware Solution (OCVS)
- IBM : IBM Cloud for VMware Solution
- Alibaba : Alibaba Cloud VMware Service
Dans cet article, nous comparerons les 4 offres leaders sur le marché : Amazon, Google, Azure et Oracle.
Toutes ces solutions permettent aux DSI d’accélérer un mouvement de move to cloud, pour ceux qui suivent un plan de transformation digitale dont la stratégie serait d’externaliser ses applications métiers vers le cloud public.
Il peut s’agir d’une première étape, un premier mouvement, permettant de déplacer facilement ces workloads VMware sans faire de big bang technique et organisationnel, pour ensuite de prendre le temps de moderniser ses applications, au fil de l’eau et en douceur. Ou encore de consolider dans le Cloud Public des workloads « Legacy » au côté d’autres dans formats plus natifs des Cloud Providers (IaaS, PaaS …).
Un modèle de responsabilité partagé avec des engagements de service (SLA)
Les cloud providers proposent un modèle de responsabilité partagée, avec des opérations dont ils ont la charge et la responsabilité, et des opérations qui sont à la main du client. Ils peuvent ainsi proposer des engagements de service fonctions de leur niveau de responsabilité ainsi que de la topologie du cluster VMware.
Administration technique : qui fait quoi ?
Cas général et exception OCVS
Sur AWS, AVS, et GCVE, ne vous attendez pas à disposer du compte root super administrateur vSphere, celui-ci est réservé au cloud provider.
Que le compte s’appelle cloudadmin (AVS et AWS) ou cloudowner (Google), le compte principal à disposition du client dispose de privilèges limités. Impossible de se connecter aux ESXi en ligne de commande, de modifier les politiques de stockage vSAN, d’ajouter des utilisateurs locaux, ou de mettre en maintenance un ESXi ou le cluster vSphere. Inutile car ces opérations sont de la responsabilité du fournisseur, qui gère le déploiement, l’administration, les mises à jour, la sauvegarde des configurations (et non celle des VMs), sur l’ensemble des outils VMware.
Seul Oracle offre tous les accès VMware à son client final, et pour cause, Oracle n’aura plus accès à la couche VMware suite au déploiement de l’environnement. L’intégralité des opérations sont à mener par le client, ce qui offre le contrôle total du déclenchement de toutes les opérations, mises à jour, maintenance du cluster, configuration du stockage et propagation de règles de sécurité dans le cas d’interconnexion entre un vCenter On-Prem et un vCenter sur OCVE.
Donc pour toutes les solutions sauf Oracle, si vos outils de CI/CD, monitoring ou sauvegarde nécessitent des accès privilégiés à vSphere, il faudra soit faire une demande au support, dans le cadre de Microsoft, soit utiliser des comptes de service locaux pré-provisionnés dans le cas de Google et AWS.
Sur l’administration côté cloud provider, l’offre AWS se détache de ses concurrents par le fait que c’est VMware qui opère le maintien en condition opérationnel de l’environnement.
Versions des composants VMware
Comme nous venons de le voir, VMware opère l’infrastructure de l’offre VMware Cloud on AWS. Quel est l’avantage ?
Le gain principal, au-delà de la maîtrise parfaite de sa propre solution, réside dans l’alignement de la roadmap produit, et donc une disponibilité des nouvelles versions VMware plus rapide sur AWS que sur les autres solutions.
Pour donner un exemple concret : vCenter 8.0 a été publiée en octobre 2022 par VMware. A ce jour, la version 8.0 de vSphere est disponible uniquement VMC AWS, là où la dernière version proposée par Azure et Oracle est la version 7.0 U3c, et 7.0 U2d chez Google. Ce critère peut être différenciant important, notamment avec les failles de sécurité impactant VMware ESXi remontées au premier trimestre 2023.
Versions actuellement disponibles :
VMC 8.0.0 / GCVE 7.0 U2d / AVS 7.0 U3c / OCVS 7.0 U3c
Modèle de responsabilité partagée
Voici un tableau illustrant le modèle de responsabilité partagé pour ces 4 solutions :
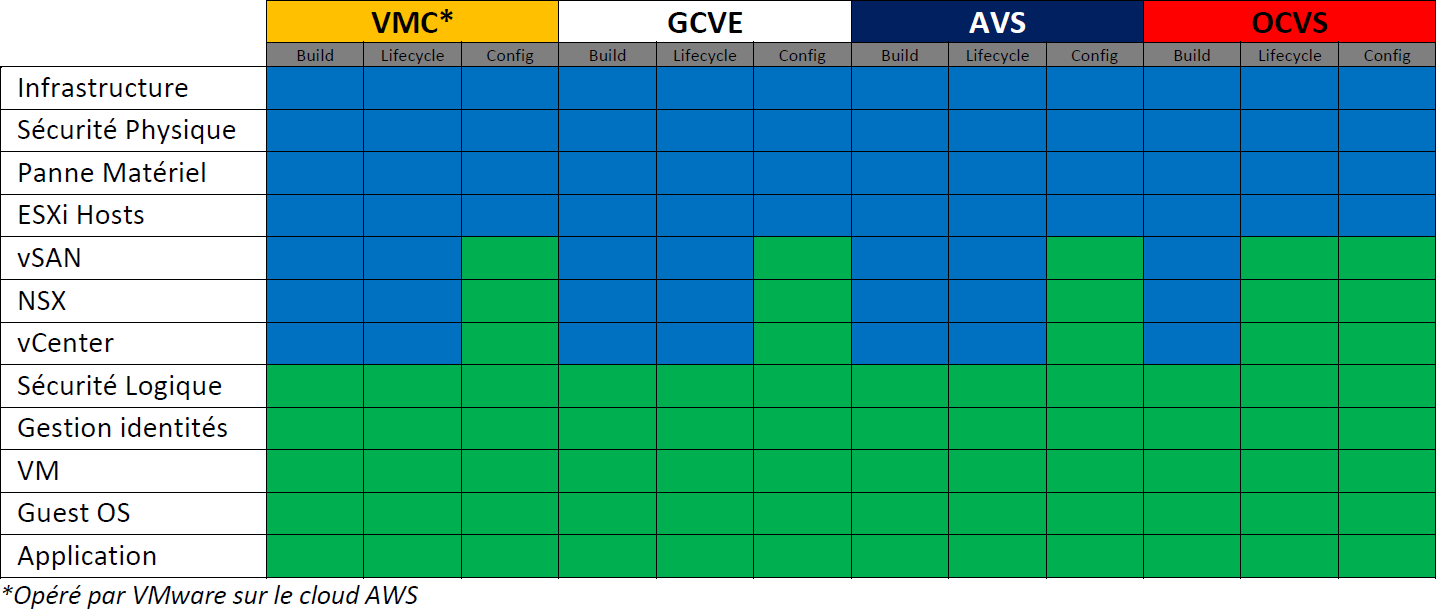
Bleu : responsabilité du fournisseur
Vert : responsabilité du client
Intégration dans les consoles des fournisseurs
L’intégration dans les consoles GCVE et Azure permettent toutes les deux de déployer l’environnement et de réaliser des opérations de base, comme l’ajout d’un nœud, le déploiement d’un segment NSX, configurer l’authentification vSphere en SSO, etc. Ces opérations sont également possibles via les CLI des fournisseurs.
Oracle et AWS : contrairement aux autres solutions, il n’y a pas d’intégration de VMware dans la console du Cloud Provider. Le seul moyen d’administrer VMware Cloud on AWS est d’utiliser la Cloud Console ou bien vCenter.
Topologie de cluster VMware et engagement de service
Rappel : Infrastructure hyperconvergée et principes de tolérance de panne
Les principes de tolérance de panne évoqués ci-dessous ne sont pas propres au Cloud Public ni à VMware mais concerne globalement toute infrastructure hyperconvergée utilisant du stockage partagé et distribué : VMware vSAN, HPE Simplivity, Nutanix, VXrail, etc.
Rappelons que les solutions proposées sont des architectures de type hyperconvergée (HCI) ou les Hosts (ESXi) embarquent des disques durs, présentés aux nœuds sous forme de volume de stockage virtualisé (vSAN). Dans cette topologie, la tolérance de panne se base sur des mécanismes de réplication des données entre plusieurs nœuds.
Comme le niveau RAID sur disque dur dépend du nombre de disques durs disponibles dans le groupement de disques, le niveau de tolérance de panne dans une infrastructure hyperconvergée dépend du nombre de nœuds disponibles dans le cluster, ainsi que du nombre de copies de la donnée souhaitée.
A minima, le cluster doit pouvoir tolérer la perte ou le retrait d’un nœud sans perte des données et de disponibilité des workloads, à l’occasion d’un incident, d’une maintenance sur un nœud, ou d’une mise à jour de VMware ESXi.
Voici les recommandations VMware pour un environnement on-prem :
- 4 nodes for RAID1 ftt1 (3+1)
- 7 nodes for RAID6 ftt1 (6+1)
Pour un environnement on-prem, le +1 est intéressant car en cas de perte de nœud, le RPO/RTO est garanti avec un nœud de secours, prêt à intégrer le cluster ou déjà présent dans celui-ci. Sur les offres de cloud public, en cas de défaillance d’un nœud, des processus automatiques sont censés exécuter le remplacement automatique d’un nœud en défaut avec tout ce que cela implique comme opération (et des possibles baisses de performance associées) :
- mise en maintenance du nœud ou suppression forcée,
- retrait du nœud du cluster,
- ajout d’un nouveau nœud dans le cluster,
- nouvelle répartition des données entre les nœuds,
- sortie du mode maintenance.
Aussi, les capacités techniques (vCPU, RAM, Disque) du cluster pour exécuter vos workloads dépendra de plusieurs critères :
- Votre politique de tolérance de panne et la configuration vSAN associée (configuration par défaut puis par VM),
- La topologie du cluster (nb de nœuds dans le cluster, espace de stockage brut par nœud, vCPU, vRAM)
- Le respect des seuils des engagements de service (ex : ne pas dépasser 80% de charge CPU ou RAM),
- Les ratio de compression et déduplication vSAN, dépendant de vos données.
Les solutions Oracle, Google et Amazon permettent un démarrage sur 1 nœud, pour un usage hors production, et sans support. Les SLA s’appliquent ensuite à partir de 2 nœuds chez AWS et 3 nœuds chez AVS et GCVE.
Un point de vigilance important : les SLA sont applicables à condition de respecter des seuils de consommation sur les CPU, la RAM, et de stockage. Dit autrement : pour rester dans le cadre des engagements de service, il faut prévoir de la capacité technique libre, non allouée dans son capacity planning et ne pas considérer que tout l’espace libre est utilisable pour mettre des VM. Cela concerne aussi bien le CPU, que la RAM et le stockage.
Pour estimer vos besoins en stockage, vSAN Capacity est un outil intéressant permettant d’estimer l’espace disponible pour vos workloads en fonction de la topologie du cluster vSAN.
Ci-dessous par exemple la comparaison de la répartition du stockage entre un scénario RAID1 / 3 noeuds et un scénario RAID5 / 4 noeuds :
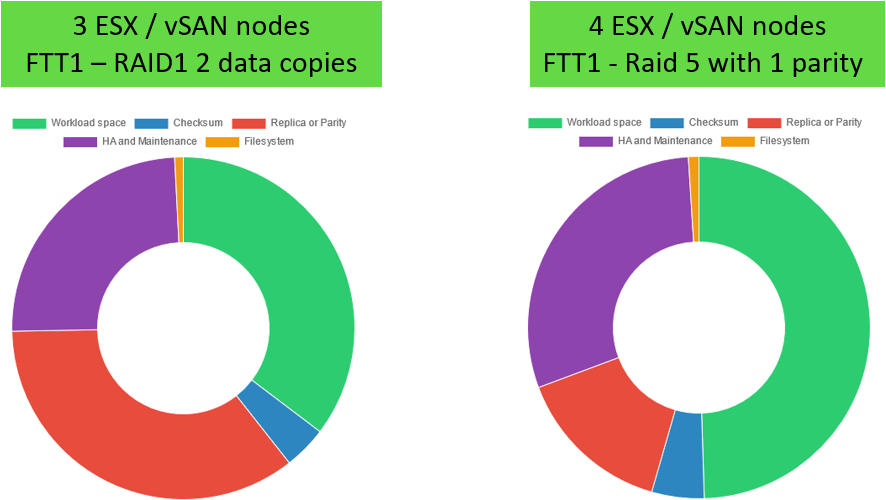
Exemple 1 : Pour un cluster de 3 noeuds, avec une tolérance de panne de 1 noeud (FTT-1), et des VM repliquée sur au moins 2 noeuds (RAID1), compter environ 35% de l’espace brut total disponible pour vos workloads.
Exemple 2 : Pour un cluster de 4 noeuds, avec une tolérance de panne de 1 noeud (FTT-1), et 1 noeud (équivalent 1 noeud) de parité dans le cluster (RAID5), compter environ 50% de l’espace brut total disponible pour vos workloads.
Source : https://kauteetech.github.io/vsancapacity/.
Exemple de SLA
Un exemple d’engagement de service en fonction de la typologie du cluster, sur l’offre GCVE :

Source : https://cloud.google.com/vmware-engine/sla
Les offres techniques
Dans ce chapitre, nous comparerons les configurations techniques possibles pour déployer un cluster, les bases communes à chaque offre, les limites connues, les spécifications techniques.
Chaque solution se base sur des fondations VMware commune, et intègre un serveur vCenter, vSphere, NSX pour la gestion du réseau virtualisé, HCX en version standard ou Enterprise pour gérer la migration de vos workloads. Une fois le setup réalisé, vous disposerez des interfaces VMware traditionnelles, que ce soit via vSphere ou via les API VMware.
Type de nœuds disponibles et coûts
Le tableau ci-dessous donne des informations sur les capacités techniques des nœuds et le coût par mois, pour la région France ou Europe.
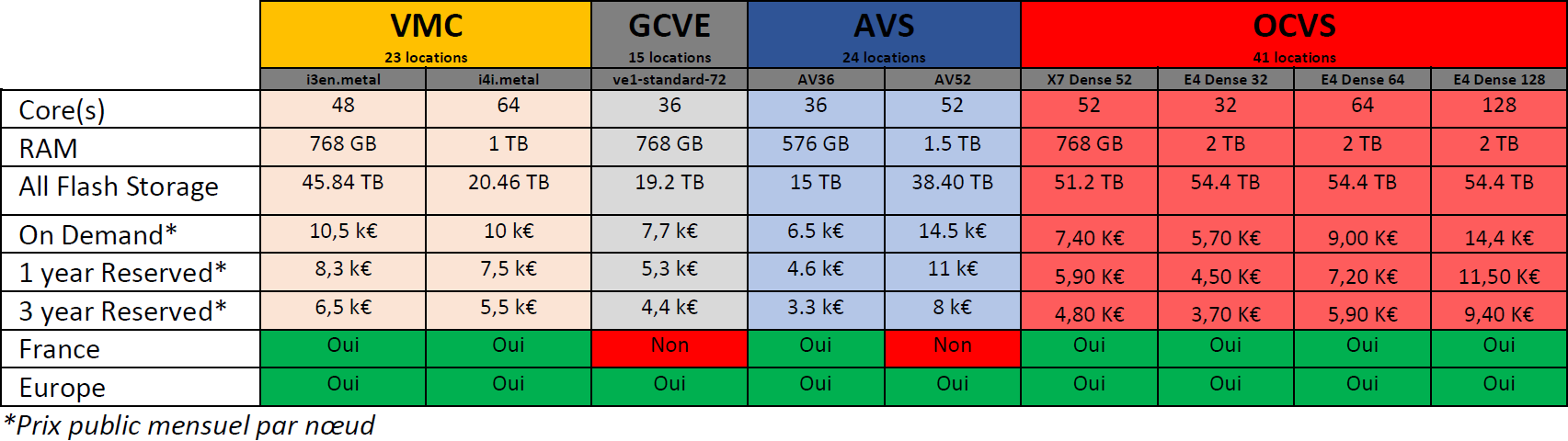
A la lecture et en complément de ce tableau :
- Toutes les offres proposent du stockage full flash,
- OCVS dispose du meilleur ratio de capacité technique / coût (mais propose aussi moins de services managés),
- OCVS propose d’un plus grand choix de nœud que ses concurrents, de nœuds ayant le plus de capacité technique, et le plus de région (41),
- A coût équivalent, les nœuds proposés par GCVE sont plus performants que les nœuds proposés par Microsoft,
- GCVE est la seule offre limitée à un type de nœud,
- L’offre GCVE n’est pas disponible en France.
Le choix du type de nœud dépend essentiellement de la typologie de workloads que vous prévoyez de migrer sur l’environnement. Il peut être utile de travailler sur la base d’un gabarit type pour estimer vos besoins. Cette approche vous permettra de comparer des coûts unitaires par VM en fonction des scénarios, et d’avoir une base comparable avec des coûts d’hébergement on-prem ou chez d’autres fournisseurs, ou des coûts de machines virtuelles au format proposé directement par les hyperscalers.
Quelques questions à se poser dans sa réflexion :
- Mon activité nécessite-t-elle un hébergement des données en France ?
- Les besoins entre vCPU, vRAM et stockage sont-ils équilibrés ? Ai-je davantage besoin de vCPU, de vRAM, ou de stockage ?
- Comment va évoluer mon besoin pour ces prochaines années ?
- Quels sont les coûts indirects de mes licences ? (License Windows Datacenter par core?)
D’autres critères peuvent être intéressants à comparer, comme la proportion d’énergie renouvelable utilisée pour alimenter le datacenter du fournisseur de cloud. Certaines régions en Europe ont une proportion très importante d’énergie renouvelable comparées aux énergies fossiles.
Overheads système VMware
A noter que les machines de management VMware pour porter vCenter, NSX et HCX consomment des ressources directement sur le cluster VMware, ressources qui seront par conséquent indisponibles pour vos workloads. Autant HCX peut être utilisé temporairement pour des migrations, autant ce n’est pas le cas pour vCenter et NSX. Plusieurs machines virtuelles sont nécessaires sur chaque nœud pour faire fonctionner le réseau NSX (machines Edge et Manager), machines virtuelles dont la taille est dimensionnée en fonction de la taille des nœuds : plus les nœuds sont gros, plus les besoins réseaux seront importants, plus les machines virtuelles NSX auront des capacités techniques importantes.
Pour un cluster de 3 nœuds, il faut estimer un overheads pour le système VMware d’environ 60 vCPU, 200 Gb de RAM, 2 Tb d’espace disque.
Disponibilité en Région et en France
Sur l’offre AVS, GCVE et VMC, le déploiement de l’offre a été progressif, et ne couvre pas l’ensemble des régions. Chez Oracle, tous les nœuds sont disponibles dans toutes les régions.

Si votre activité nécessite un hébergement sur le territoire François, alors l’offre de Google sera exclue. La disponibilité de GCVE en France ne semble pas prévue dans la roadmap.
Stretched cluster
Contrairement à ses concurrents, Azure ne propose pas d’architecture VMware en Stretched cluster, permettant de la haute disponibilité régionale, ni d’autoscaling du cluster VMware (ajout/retrait de nœud dans le cluster suivant la charge globale du cluster). L’ajout d’un nœud passe par un ticket au support, il faut donc anticiper !
Accessibilité et Landing Zone
Pour accéder à votre environnement VMware chez le cloud provider, il convient de disposer en amont d’une landing zone. En effet, l’environnement VMware seul doit être intégré dans l’architecture réseau pour être accessible, que ce soit pour son management, ou pour que les workloads vSphere puissent communiquer à l’extérieur de VMware.
Les environnements peuvent être créés soit dans les souscriptions existantes (Oracle), soit dans des souscriptions dédiées (AVS, VMC, GCVE).
Les meilleures pratiques pour l’exécution de workloads VMware sur le cloud public
Dans ce chapitre, nous évoquerons les principaux sujets permettant l’exécution et l’exploitation technique de workloads VMware dans les solutions des clouds providers.
Nous aborderons :
- la connectivité réseau,
- la planification de la migration des workloads avec VMware HCX,
- l’évolutivité,
- la sauvegarde,
- la réplication et le DR,
- la supervision.
La connectivité réseau
Que vous choisissiez une offre ou une autre, une des premières étapes de votre déploiement sera d’interconnecter votre datacenter on-premise avec votre nouvelle infrastructure VMware.
Deux options s’offrent à vous :
- déployer un tunnel VPN IPsec et utiliser Internet,
- déployer une interconnexion dédiée (Expressroute Global Reach, Direct Connect, Cloud Interconnect, etc.).
Suivant le provider et votre besoin, l’architecture réseau à déployer pour l’interconnexion et pour la migration de vos workloads peut vite s’avérer complexe et nécessiter le déploiement de routeur intermédiaire, à la main du fournisseur).
Dans ce type de projet et bien que ne concernant pas directement VMware, le réseau un élément fondamental à ne pas sous-estimer. Les différents retours d’expérience que j’ai fait avec des clients finaux sont unanimes sur le sujet.
Au sein de VMware, vous serez obligé de configurer et d’utiliser NSX-T. Vous pouvez également compléter en exécutant sur VMware vos machines virtuelles de routage / firewalling (NVA), en prenant là aussi le risque de rendre complexe l’architecture réseau. Il est possible de forwarder vos logs NSX vers un collecteur ou siem de votre choix.
Planifier la migration
Solution HCX, le standard VMware
Pour la migration de vos machines virtuelles, toutes les solutions permettent l’utilisation de VMware HCX, en version Standard ou Enterprise. HCX vous permet de planifier des migrations par lot, avec différentes approches techniques possibles, de la migration à froid avec un changement d’IP, à la migration à chaud sans changer d’IP.
La migration à chaud nécessite de faire une extension de niveau 2 entre le site on-prem et le cluster VMware dans le cloud. Le site on-prem doit respecter un certain nombre de prérequis (Version de vCenter et ESXi, licence VMware Enterprise, réseau NSX, déploiement appliance HCX sur chaque ESXi, etc.). Une architecture réseau spécifique doit être maintenue durant toute la phase de migration.
D’après plusieurs retours d’expérience client, la préparation du site on-prem ne doit pas être sous-estimée pour assurer l’extension du réseau avec HCX. La liste des prérequis est importante : https://docs.vmware.com/en/VMware-HCX/4.5/hcx-user-guide/GUID-741F47D5-A3C9-4D74-9672-E54D8791D8F0.htm
Solutions alternatives pour la migration de vos workloards
Fonction de votre écosystème existant, l’utilisation d’autres solutions compatibles est possible : Veeam, Commvault, Cohesity, Zerto, etc.
Que vous utilisiez ou non la solution HCX, le coût des licences est inclus dans la solution globale.
Les points de vigilances à rappeler :
- la préparation du site on-prem et les prérequis à respecter,
- la configuration du réseau étendu niveau 2 entre le site on-prem et le site de destination NSX,
- la consommation de ressource sur chaque ESXi pour déployer les appliances HCX (minimum 3),
- l’absence de conversion possible vers des formats autre que VMware dans HCX (ec2 ou autre).
L‘évolutivité
Les solutions techniques permettent un scaling horizontal simple, par l’ajout de nœud ESXi dans le cluster existant. L’ajout d’un nœud permet d’augmenter la capacité technique du cluster sur la partie compute et stockage vSAN, ainsi que le réseau.
S’il le besoin est uniquement d’augmenter le stockage, alors il est possible de présenter au cluster vSphere des volumes de stockage via des services intégrés des cloud provider. Il est par exemple possible de déposer des ISO et des templates VMware sur un volume Blob Azure ou un Bucket S3, qui sera monté comme un datastore et partagé à plusieurs clusters VMware.
Il est aussi possible de présenter un volume Netapp (Cloud Volume ONTAP) sur toutes les solutions : GCVE, AVS, VMC et OCVS.
Les bases de données volumineuses peuvent être hébergées en dehors du cluster, sur des services managés par le cloud provider (Azure SQL Database, AWS RDS, Aurora, etc.).
Il est aussi possible de déployer plusieurs clusters VMware pour permettre d’avoir davantage de capacité technique ou une répartition de son infrastructure dans plusieurs régions.
La sauvegarde
Concernant la sauvegarde de VM, le client en a l’entière responsabilité.
Par défaut, rien n’est configuré dans les offres et les coûts de la sauvegarde n’est pas directement inclus dans les calculateurs en ligne.
Toutes les solutions sont compatibles sur le papier avec les solutions de sauvegarde « native » du cloud provider, bien que celle-ci ne soit pas conçue initialement pour sauvegarder des machines VMware.
Par exemple, vous pouvez utilisez Azure Backup pour sauvegarde vos VM VMware sur AVS. Cela nécessitera le déploiement d’un serveur Azure Backup Server dédié, ainsi que d’un volume de stockage dédié qui sera utilisé comme un repository pour vos backups. Il faut prévoir un coût associé à ce serveur de sauvegarde, son compute et son stockage.
Sur AWS, l’utilisation d’AWS backup est également possible.
Les différents retours d’expérience des fournisseurs, partenaires et clients finaux sont unanimes sur le sujet : en général, l’outil de sauvegarde utilisé n’est pas l’outil natif du cloud provider, mais la solution en place sur l’environnement existant du client. Ces solutions sont nativement prévues pour la sauvegarde de VM au format VMware, elles sont connues et maîtrisées par les équipes en place, et sont certifiées par les cloud providers : Commvault, Cohesity, Veeam, Rubrik, etc.
Configurer ces solutions pour sauvegarder un nouveau cluster VMware dans le cloud public n’est pas compliquée et permet de conserver un écosystème technique cohérent. Cela peut nécessiter le déploiement de proxy, appliance, repository dans le cloud, ou l’utilisation de solution de sauvegarde directement dans le Saas.
Attention aux déploiements de solution de sauvegarde sur la même région que la production, ainsi que coût des flux sortants pratiqués par certains fournisseurs.
La réplication et le DR
Plusieurs options s’offrent à vous.
Sur certaines solutions, vous pouvez déployer des stretched cluster VMware, permettant une recopie de données entre plusieurs régions. Vous pouvez aussi déployer plusieurs clusters dans plusieurs régions et mettre en œuvre la solution historique de VMware : VMware Site Recovery Management, qui a fait ses preuves depuis plus de 15 ans ! VSRM est compatible avec toutes les solutions mais le coût de la licence n’est généralement pas inclus dans le prix des nœuds.
Les autres solutions du marché comme Zerto ou Rubrik sont compatibles et peuvent vous permettre de mettre en œuvre facilement vos plans de reprise d’activité en répliquant vos machines VMware d’un cluster à l’autre. Un avantage pour ces solutions, notamment Zerto réside dans leur capacité :
- à faire de conversion de format pendant la réplication,
- à ordonnancer la configuration et le redémarrage des services (changement d’adresse IP, changement de vlan, démarrage, contrôle, etc.),
- à planifier des tests réguliers,
- à faire des rapports de conformité du plan de reprise d’activité (preuves pour des auditeurs lors d’audit ISO ou PCI, etc.),
Par exemple, il est possible de répliquer une machine dont le format source sera VMware, vers un format de VM Azure ou AWS EC2. Dans le cas, la machine qui sera démarrer dans le cadre du PRA s’exécutera directement au format du cloud provider, et non VMware.
Une solution plus récente sur le marché est VMware Cloud Disaster Recovery (VCDR), qui est une solution plus récente que VSRM et adaptée au cloud public, et qui permet de répliquer et d’orchestrer le redémarrage d’un SDDC complet sur AWS ou sur GCVE.
La supervision
Utiliser la solution de votre choix, ce n’est pas un sujet. Une fois le compte de service provisionné, les outils de supervision standard du marché sauront superviser vos ESXi.
Critères de sélection d’une solution VMware dans le cloud public
Nous comparerons dans ce chapitre les offres sur des critères clés que les entreprises peuvent prendre en compte lors du choix d’une solution, tels que la sécurité, l’évolutivité, la compatibilité, le coût et le support. Sans que cette liste soit exhaustive, voici quelques critères :
La souveraineté : Toutes les offres sont disponibles en France, à l’exception de GCVE.
L’évolutivité : Toutes les offres permettent d’ajouter des nœuds dans le cluster. Parfois c’est automatisé (VMC, GCVE), parfois non (AVS). Oracle propose des clusters jusqu’à 64 nœuds ! Avant d’atteindre ces limites, qui sont les limites VMware, vous préférerez répartir vos workloads sur plusieurs clusters afin de cloisonner des périmètres et limiter des risques.
La disponibilité (stretched cluster) : Toutes les offres permettent de déployer des Stretched Cluster avec des nœuds sur plusieurs sites, à l’exception d’AVS.
Le coût : Meilleur rapport capacité technique / prix pour Oracle, mais des tailles de nœuds qui peuvent dépasser le besoin de plus petite infrastructure. Attention, même si le coût facial d’un noeud Oracle est très bien placé, ne pas oublier qu’il y pas le service managé offert par les autres fournisseurs, coût qui sera porté par votre équipe technique ou un infogérant.
le support : qui de mieux que VMware pour opérer votre plateforme VMware ? un bon point pour l’offre VMware Cloud on AWS, où les équipes VMware travaillent de pair avec Amazon sur la gestion de l’infrastructure. Votre point de contact est directement VMware.
Le contrôle : vous souhaitez être le seul maître à bord ? choisir vos versions ? la planification de vos montées de version ? avoir la main sur les règles de sécurité réseau ? souhaitez-vous opérer vous-même votre infrastructure VMware dans le cloud public ? L’offre OVCS laissera le contrôle complet à votre équipe, quand les autres offres de services sont managées par le fournisseur.
Votre legacy : Vous disposez peut-être déjà d’un contrat et exécuter des services sur AWS, Azure, OCI ou GCE ? Votre stratégie impose de diversifier ou au contraire de consolider vos infrastructures ?
La réversibilité : Toutes les offres se basant sur un format de machines virtuelles VMware classique, le retour arrière on-premise de vos workloads n’est pas un sujet si vous disposez d’une autre infrastructure VMware.
La sécurité : Les mises à jour logiciels du SDDC sont en avance sur VMware Cloud on AWS par rapport aux autres offres. Toutefois, comme vous avez la main sur OCVS, vous être libre de faire des upgrades à votre rythme. A noter que la sécurité logique est de l’entière responsabilité du client dans l’ensemble des offres.
Conclusion
Comme nous l’avons vu dans les chapitres précédents, bien que les offres se basent toutes sur des fondamentaux VMware, les implémentions ont quelques différences.
En prenant en compte uniquement les offres techniques et financière, 2 offres nous semblent se distinguer.
- VMware Cloud on AWS semble leader, avec l’appui exclusif de VMware pour la gestion de l’infrastructure,
- OCVS d’Oracle, différenciant des autres par son modèle de responsabilité à la main du client, sa forte disponibilité en région, et la capacité importante des nœuds.
Dans les offres managées, celles de Microsoft et Google semblent être des suiveurs, et n’ont pas l’exclusivité d’avoir VMware à la manœuvre pour opérer la plateforme.
Le point commun à l’ensemble des offres est la rapidité de la migration de vos workloads VMware dans le cloud, et le fait que vos administrateurs systèmes ne seront pas perdus face à une console vSphere. En maximum 2 ou 3 semaines, l’ensemble de l’architecture peut être prête pour recevoir et exécuter vos workloads VMware.
Les points de vigilances importantes à retenir avant de se lancer dans un déploiement VMware dans le cloud public :
- Ne pas sous-estimer la complexité de l’architecture réseau,
- Ne pas sous-estimer la préparation du site on-prem si vous souhaitez utiliser HCX,
- Bien réfléchir au niveau de responsabilité souhaité (contrôle ou délégation ?),
- Bien réfléchir à son écosystème global (supervision, sauvegarde, DR, multi-région, etc.),
- Définir en amont sa feuille de route pour la migration des workloads.
Des nombreux assessment sont disponibles auprès des fournisseurs pour vous aider à qualifier vos projets.
Ci-dessous un tableau de synthèse classant les fournisseurs sur certains critères :

Nous espérons que vous avez apprécié la lecture de cet article. N’hésitez pas à commenter ou nos poser vos questions.

Dérouler son exercice de gestion de crise cyber
C’est le jour J : vous avez défini les contours de votre exercice, vu le casting, préparé les stimuli et le chronogramme, briefé les participants sur ce que l’on attend d’eux, préparé les documents support (main courante …). Maintenant nous déroulons l’exercice !
Appliquer ce qui est prévu
Les équipes démarrent par un rappel des objectifs et des règles de l’exercice ainsi qu’une mise en situation pour redonner le cadre de l’exercice.
Les animateurs s’appuient sur le chronogramme et le respectent (on a dit ce que l’on ferait, on fait ce que l’on a dit), tout en sachant s’adapter (voir ci-dessous).
Il est possible de concrétiser certains impacts (par exemple si le PC du DSI est compromis, on peut lui demander de ne pas l’utiliser pendant une partie de l’exercice !). Il en est de même pour certaines mesures de contournement ou de limitation de la propagation (s’isoler du réseau …).
Mais savoir s’adapter
Suivre le chronogramme du mieux possible : oui, pour autant il est nécessaire de s’adapter aux joueurs pour ne pas les perdre.
S’il faut décaler tel ou tel stimuli prévus à tel moment dans le chronogramme (le temps que l’utilisateur réponde au stimuli précédent) mais que c’est pour le bien de l’exercice alors il faut le faire. Si l’on doit trop modifier le chronogramme, une décision collégiale du groupe d’animateurs est requise pour s’assurer que tout le monde est aligné.
Conseil : le guide de l’ANSSI indique que généralement 70% des stimuli du chronogramme sont respectés et que 30% sont remaniés voir improvisés (généralement suite à des questions ou réactions de joueurs que l’on n’avait pas anticipé). Essayez de rester dans ces proportions !
Connaitre les principaux écueils pour les éviter
Quand bien même l’exercice est préparé, la manière dont chacun réagit le jour J n’est pas connue par avance.
Les écueils courants sont (le guide donne des recommandations) :
- La cellule de crise décisionnelle devient une cellule de crise opérationnelle
- Incompréhension entre décisionnels et opérationnels
- Contradiction entre les décisions prises et l’objectif de l’exercice
- Sur sollicitation d’équipes techniques au détriment des joueurs impliqués
- Manque de compréhension et d’explication des problématiques cyber
A cela on pourra ajouter le manque d’implication de certains joueurs qui attendent d’être sollicités par les autres. A l’inverse certains sont omniprésents et “étouffent” les autres joueurs leur laissant peu de place.
Tirer les enseignements (REX)
Le retour d’expérience est un élément important de l’exercice car il permet d’en évaluer la pertinence, l’efficacité etc. et donnera des éléments factuels et structurants pour améliorer le suivant.
Organiser un retour d’expérience à chaud
En fin d’exercice un animateur fait un tour de table avec l’ensemble des participants (les joueurs puis les observateurs, pour ne pas influencer les joueurs) .
On y parle pas que du jour J mais aussi de la préparation, du scénario, de la qualité de la communication, de la logistique (salle …), du casting … il est important que chaque participant prenne la parole.
Eventuellement un petit questionnaire permet de formaliser les points clefs attendus durant le retour d’expérience.
Organiser un retour d’expérience à froid
Ce REX est plus formel et plus détaillé ; une ou plusieurs restitutions sont à prévoir (une restitution très générale/managériale, une autre plus détaillée pour les équipes opérationnelles). Bien entendu toutes ces réunions ont été planifiées bien en avance, avant même de réaliser l’exercice. Ce sont des jalons de notre projet “organiser un exercice de gestion de crise cyber”.
La main courante et le REX à chaud sont des éléments importants pour la création du REX à froid, tout comme les mails échangés durant l’exercice et le retour des observateurs.
Il faut un REX juste et équilibré, avec les points faibles mais aussi les points forts. Il doit être synthétique et se baser sur des éléments factuels.
Un plan d’action synthétisera les améliorations à apporter pour le prochaine exercice (de la conception à la tenue de l’exercice).
Conclusion
Cet article conclut cette courte série dont l’objectif est de vous donner envie de consulter le Guide de l’ANSSI : “Organiser un exercice de gestion de crise cyber”.
Bien organiser l’exercice, d’autant plus quand c’est le premier, demande pas mal de préparation et de temps.
Mieux vaut démarrer avec un exercice court et pragmatique pour mettre le pied à l’étrier, sensibiliser les parties prenantes et les faire adhérer à la démarche.
L’animation de l’exercice en lui même est un élément clef du succès de l’exercice à condition d’avoir un chronogramme bien pensé et des stimuli vraisemblables. Il faut donc :
- passer/investir suffisamment de temps sur la préparation : 20 à 30 jours*homme pour un exercice court, (10 c’est pas assez, 50 ca fait trop)
- répéter l’exercice entre animateurs avant de le dérouler réellement.
- s’adapter aux réponses/réactions des participants sans frustration de part et d’autre
L’équipe Iwyco et ses partenaires peuvent vous accompagner dans la préparation et la tenue d’un tel exercice, ou plus en amont par la réalisation d’un “serious game” qui aura la vertu de sensibiliser certains décideurs au sujet et de débloquer du budget pour préparer plus sereinement un premier exercice.
Dans notre précédent article, nous avons vu la partie “Conception” (ce qu’on souhaite faire) d’un exercice de gestion de crise cyber en suivant le guide de l’ANSSI et du CCA. Ici nous traitons de la partie “Préparation” (comment on va le faire), qui est normalement la plus consommatrice en temps.
Préparer son exercice de gestion de crise cyber
En sortie de la phase de Conception nous avons pu formaliser le contexte, la durée, les objectifs, le thème, les participants etc de notre exercice de gestion de crise.
Il s’agit maintenant de mettre cela en musique et de préparer concrètement cet exercice, principalement via des stimuli et un chronogramme.
Définir le scénario
Le scénario prévoit un évènement vraisemblable conduisant à l’activation de la cellule de crise sur le thème que l’on a choisi (phishing, ransomware …).
Il couvre à minima les phases de réaction immédiate et d’investigation, et pas obligatoirement la phase de remédiation. (Celle-ci peut faire l’objet d’un autre exercice que l’on déroule quelques mois plus tard en continuité du premier)
Le scenario :
- a pour point de départ une attaque informatique,
- prévoit des conséquences et impacts métiers,
- contient des détails techniques sur l’attaque,
- tient compte de l’environnement de l’organisation (contraintes réglementaires, écosystème …).
La résolution technique de la situation est à envisager lorsque l’exercice est limité à une demi-journée ou moins.
Conseil : évitez un scénario catastrophe ou peu vraisemblable qui provoquerait un désengagement des participants. Pour cela, interviewez les experts, cela permettra également d’affiner le chronogramme et son réalisme.
Conseil : Pour un premier exercice, proposer une sortie de crise immédiatement en fin de scénario peut donner l’impression qu’une crise cyber se résout rapidement.
Prévoir et rédiger les stimuli
Les stimuli sont à préparer/rédiger avant l’exercice. Ce sont des éléments clefs de votre exercice de gestion de crise cyber.
Cela peut-être des emails, un script téléphonique à suivre avec un ou plusieurs des joueurs, une copie d’écran simulant un message lié à une intrusion, un fichier de log fictif, un message du hacker sur les réseaux sociaux indiquant qu’il a attaqué avec succès votre organisation …
Conseil : prévoir quelques stimuli complémentaires / de rechange pour s’adapter à la réaction des participants durant l’exercice car ceux-ci ne suivront peut-être pas le script parfait que vous aviez imaginé.
Conseil : sur un scénario basé sur un 0-Day, le CERT FR recense les vulnérabilités les plus récentes et les plus graves, ce qui peut être source d’inspiration.
Rédiger le chronogramme
Le chronogramme est un tableau qui décrit le déroulement chronologique de l’exercice en ligne à ligne. Il intègre les stimuli et les interactions entre les joueurs et les animateurs. Ces derniers doivent savoir s’adapter aux réactions des premiers.
Il est crucial d’interviewer les experts pour bâtir ce chronogramme pour qu’il soit vraisemblable, sous peine de démobiliser les joueurs durant l’exercice de gestion de crise cyber.
Le chronogramme définit le rythme et l’intensité de l’exercice. il ne se déroule pas en temps réel mais en temps accéléré car certaines phases peuvent prendre du temps (des investigations par exemple).
Même en temps accéléré il est possible de faire ressentir la longueur de certaines actions ; par exemple envoyer un stimuli toutes les 2 à 3 minutes en phase de détection de l’attaque (on découvre que tel ou tel site est lui aussi compromis), puis attendre 10 à 15 minutes pour avoir le résultat des investigations.
Sachez que cela va créer de la frustration et des incertitudes, qu’il faudra le gérer et que c’est normal. Quand un participant dit “appelez le SOC pour savoir comment les hackeurs sont rentrés, s’ils ont exfiltrer de la donnée”, il ne faut pas s’attendre à avoir toute les réponses en quelques minutes dans l’exercice (ce qui correspondrait à quelques heures seulement “dans la vraie vie” où c’est bien souvent plus long).
Conseil: renvoyer des éléments inconnus que l’on complète au fur et à mesure du chronogramme renforce auprès des acteurs le sentiment d’incertitude inhérent à une attaque cyber.
Conseil : Le guide de l’ANSSI contient un mode d’emploi dédié à la rédaction du chronogramme avec différentes recommandations structurantes. Un exemple complet au format Excel est téléchargeable.
Option : Simuler les enjeux de communication et la pression médiatique
Les crises cyber peuvent avoir un impact sur votre image et votre réputation.
Certains exercices pourront simuler la pression médiatique (dans le chronogramme : appel de faux journalistes à des participants, faux articles de presse …). D’autres simuleront les communications internes vers l’extérieur et les parties prenantes.
Dans les deux cas l’équipe projet doit s’entourer des communicants de votre organisation ne participant pas à l’exercice pour intégrer ce(s) volet(s) au scénario.
Conseil : le guide de l’ANSSI contient un ensemble de questions types pour simuler ce type d’interaction + une fiche pratique sur le sujet.
Préparer les autres documents
L’exercice nécessite différents documents complémentaires au-delà du cahier des charges et du chronogramme, selon le public concerné.
Pour les animateurs :
- L’annuaire de l’exercice
- La main courante
- Certains stimuli (un message sur les réseaux sociaux, une copie d’écran de données exfiltrées …)
Pour les joueurs :
- L’annuaire
- Des dossiers de mise en situation (document qui plante le décor)
- Les conventions d’exercice (la règle du jeu)
- Diverses documentations utiles
Pour les observateurs :
- Fiche d’observation
- Accès à la main courante des animateurs (facultatif)
Conseil : consulter en détail les deux fiches pratiques du guide : “produire un dossier de mise en situation” et “observer un exercice”
Briefer les participants et les impliquer
Briefer tant les observateurs que les animateurs et les joueurs une à deux semaines avant l’exercice pour rappeler les objectifs de chacun et les rappeler à nouveau succinctement le jour J avant de démarrer l’exercice.
Le dernier article de cette série porte sur la réalisation de l’exercice et le retour d’expérience.
Dans notre précédent article, nous avons introduit le guide de l’ANSSI et du CCA sur l’exercice de gestion de crise cyber. Ici nous traitons de la partie “Conception”, qui est la première (suivie de Préparation, Déroulement de l’exercice, Retour d’expérience).
Concevoir son exercice de gestion de crise cyber
La phase de conception reste assez macroscopique. Elle traite plus du “quoi” que du “comment” (qui sera abordé en phase de Préparation)
L’organisation d’un exercice de gestion de crise cyber doit être adressée comme un mini projet à dérouler en cycle en V. Il a des phases et des étapes, des porteurs et des contributeurs, des livrables en entrée et en sortie, un planning à respecter, des moyens à allouer etc.
La Conception est une phase de cadrage avec pour principal livrable le cahier des charges de l’exercice.
Constituer l’équipe projet
L’équipe projet devra notamment :
- Cadrer l’exercice et définir ses objectifs
- Rédiger le scénario et le chronogramme
- Animer l’exercice
- Réaliser le retour d’expérience.
Elle est donc composée des concepteurs de l’exercice qui seront souvent les coordinateurs pendant qu’on le déroule, et pas uniquement d’acteurs qui seront “actifs” dans la résolution de la crise.
L’équipe projet a un responsable, un porteur, qui est le chef de projet de l’organisation de l’exercice.
Définir les objectifs
Selon le niveau de maturité de l’organisation et/ou la possibilité de mobiliser (ou pas) certains intervenants, les objectifs pourront être de différentes natures :
- Sensibiliser les participants aux problématiques cyber (pour ceux habitués de la continuité d’activité “classique” par exemple)
- Former et entrainer le personnel (cela peut inclure des prestataires clefs comme un hébergeur/infogérant)
- Tester le dispositif de gestion de crise cyber (chaines d’alertes, outils utilisés …)
Déterminer le format de l’exercice
Deux principaux formats se distinguent :
- Exercice sur table de 2 à 3 heures (prévoir 6 semaines de préparation environ)
- Exercice de simulation d’une demie journée à 2 jours (prévoir 2 à 6 mois de préparation selon la complexité)
Conseil : Cela dépendra des moyens que l’on pourra allouer à l’exercice et de la maturité des équipes sur ce type d’exercice. Evitez la simulation sur deux jours si votre organisation n’a jamais organisé d’exercice cyber auparavant.
Définir la thématique
Il faut aussi choisir le thème avec le type d’attaque (ransomware, phishing, vol de données, déni de service, défiguration de site web…).et les impacts potentiels (atteinte à la réputation, impact RGPD/CNIL, impact juridique, pertes de production …).
Il est possible de choisir son thème selon la vraisemblance du type d’attaque, ou selon le type d’impact si l’on souhaite tester telle ou telle composante de la gestion de crise (juridique, …). Pour les exercices complexes vous pouvez combiner (ransomware avec extraction de données par exemple)
Conseil : pour éviter les objections d’une équipe qui dira que ses systèmes sont inattaquables, vous pouvez prendre en scénario une faille de type “0-day” pour laquelle il n’y a pas encore de patch, ou une attaque indirecte via un prestataire par exemple.
Nommer son exercice
Comme pour un projet à qui l’on donnerai un nom, l’exercice aura son propre nom, éventuellement selon la thématique (RANSOM-01, RGPD-2022) …
Identifier les joueurs et les parties prenantes
Quatre catégories d’intervenants :
- Les experts : ils contribuent à la construction du scénario de l’exercice. Ils peuvent ensuite être animateurs ou observateurs.
- Les animateurs : ils déroulent le scénario durant l’exercice et activent les “stimuli” prévus au chronogramme. Il faut à minima un animateur + un personne gérant la main courante de l’exercice. Selon la complexité de l’exercice plusieurs animateurs peuvent intervenir en parallèle.
- Les observateurs : ils observent le fonctionnement du dispositif de gestion de crise et n’interviennent pas (contrairement aux animateurs) afin de noter les points positifs et les axes d’amélioration
- Les joueurs : ils sont ceux qui feront face à la gestion de crise sans connaissance préalable du scénario
Conseil : bien consulter les fiches du guide décrivant précisément ce que chaque persona/profil doit faire (et ne pas faire)
Conseil : quand une personne qui n’a jamais participé à un exercice est réfractaire, il est judicieux de la faire participer une première fois en observateur.
Rédiger le cahier des charges
A un moment il faut formaliser les différents choix et orientation pris durant la phase de conception.
Cela est fait dans la cahier des charges de l’exercice, qui reste un document assez synthétique mais structurant pour la suite.
Conseil : reprendre et adapter la fiche pratique “Rédiger un cahier des charges” du guide, qui est déclinée pour un exercice sur le thème des ransomwares.
Caler le calendrier
L’exercice est piloté en mode projet, il tient compte de la charge de travail nécessaire à sa préparation, aux disponibilités des participants et de la durée de l’exercice en lui-même.
Comme pour tout projet il y a quelques grands jalons:
- Une réunion de lancement avec le sponsor, les grands objectifs, un macro planning et le casting de l’équipe projet et la répartition des rôles et responsabilités.
- L’interview de différents experts pour affiner la thématique et préparer un exercice vraisemblable
- La rédaction du cahier des charges de l’exercice
- La rédaction du chronogramme (déroulé chronométré de l’exercice tel que l’on compte le dérouler)
- Des réunions de suivi de projet pour en vérifier l’avancement et les livrables
- Une réunion finale de planification de l’exercice
- Le briefing des “joueurs” participant à l’exercice, le briefing des coordinateurs et observateurs
- La date de l’exercice (+ une date supplémentaire en cas de report)
- Le REX à chaud puis le REX à froid (environ 2 à 4 semaines après l’exercice)
Conseil : être réaliste dans la planification (ne pas vouloir aller trop vite) et maintenir tant que possible les dates pour ne pas démobiliser les participants.
Prévoir la logistique
Une salle de cellule de crise, des outils à utiliser en mode dégradé (ordinateurs, moyens de communication …), des affichages pour suivre l’avancement de l’exercice et de la situation.
Si votre organisation dispose déjà de moyens spécifiques pour la gestion de crise, ré-utilisez les ou faites les amender si nécessaire pour tenir compte des spécificités d’une crise cyber.
Notre prochain article portera sur la phase de Préparation de l’exercice cyber (Comment le dérouler, chronogramme ….)

Synthèse de l’excellent guide de l’ANSSI et du CCA
L’ANSSI et le Club de la Continuité d’Activité (CCA) ont publié un excellent guide sur l’organisation d’un exercice de gestion de crise cyber. Le document est riche et dense (120 pages environ), contient de nombreux conseils et fiches pratiques (il est téléchargeable depuis cette page de l’ANSSI).
L’objectif de cette série d’articles est d’en faire la synthèse en quelques pages, certes moins riches, mais respectant au mieux la structure générale du guide et ses quatre grandes étapes :
- Concevoir son exercice
- Le préparer
- Le dérouler
- L’enrichir par un retour d’expérience
Ne nous le cachons pas :
- Les deux premières étapes sont celles qui vous mobiliserons le plus. Le guide contient d’excellentes fiches pratiques pour s’approprier plus facilement le sujet et éviter certains écueils.
- Même si sur le papier vous avez le choix du sujet de l’exercice, en 2022 ne pas simuler une crise par ransomware serait une décision … discutable.
Si votre entreprise/organisation n’est pas prête à investir le temps et l’énergie pour préparer consciencieusement un exercice de gestion de crise, un “serious game” de courte durée (1 à 2 heures) avec quelques participants clefs suffit souvent à déclencher une réelle prise de conscience et à débloquer du budget.
Introduction
Avant de reprendre chacune des 4 étapes du guide, quelques rappels sur une crise cyber.
Caractéristiques des crises d’origine cyber
Rappelons tout d’abord les spécificités d’une crise cyber, au plutôt d’une crise d’origine cyber :
- Propagation, fulgurance et ubiquité : on peut être touché à plusieurs endroits en même temps
- L’incertitude : les impacts sont souvent difficiles à estimer
- L’évolutivité : les attaquants peuvent réagir à notre réponse à incident
- La technicité : l’analyse de la situation demande une forte technicité et une bonne relation avec les acteurs non techniques
- L’élasticité dans le temps : les attaquants peuvent réitérer leur attaque si l’on n’a pas pu/su rétablir la situation ET augmenter son niveau de sécurité
- La sortie de crise est longue : répondre aux impacts immédiats peut prendre du temps, encore plus quand il s’agit de mettre en place une réponse pérenne.
- La complexité des attributions : les cyberattaques sont difficilement attribuables à un individu ou une entité en particulier.
Traitement d’une crise cyber
Les conséquences d’une cyber attaque sont diverses (opérations bloquées, pertes financières, impact légal/RH …). Il s’agit alors de coordonner des équipes variées pour endiguer les effets de la crise et rétablir le fonctionnement du système d’information.
Une cellule de gestion de crise technique travaille en parallèle d’une cellule stratégique, pour investiguer , remédier et stabiliser la situation.
Comment appréhender un exercice de crise cyber ?
L’exercice doit simuler un scénario (en aucun cas il ne doit impacter les activités réelles), dans une durée limitée, avec des évènements plausibles. L’exercice se prépare et ne s’improvise pas, il peut être limité à la partie technique/opérationnelle ou englober également la partie stratégique/décisionnelle.
S’inscrire dans une réflexion globale de résilience
Que l’origine de la crise soit cyber, il faut inscrire l’exercice de gestion de crise dans une perspective plus large de renforcement de la résilience de votre organisation et selon l’étendue de l’exercice en profiter pour :
– Sensibiliser les intervenants
– Tester l’efficacité des procédures
– Répondre ainsi à des obligations légales ou sectorielles
Idéalement l ‘exercice rentre dans un programme plus global facilitant l’apprentissage progressif et l’amélioration continue. On s’assure ainsi que le personnel maitrise les fondamentaux et n’improvisera pas totalement en cas de survenance d’une attaque cyber.
L’exercice est valorisable auprès de ses parties prenantes, de son écosystème (qui participera éventuellement à l’exercice dans le cas de prestataires clefs) mais aussi en interne pour sensibiliser son personnel.
La communication autour de l’exercice, dès les étapes de préparation, participe à sa réussite en qualifiant le public visé, les objectifs poursuivis, les messages clefs, le planning prévu (préparation, réalisation, retour d’expérience) et les ressources à prévoir pour le mener à bien.
Bien préparer l’exercice demande du temps et des ressources : un sponsor dans l’organisation facilitera l’allocation du temps et des moyens nécessaires.
Quand il est à l’initiative des équipes IT, l’exercice est d’autant plus bénéfique qu’il inclut en amont les autres services devant y participer (communication, légal …) et qu’ils ne se sentent pas jugés selon les résultats de l’exercice.
La conception de l’exercice peut être vue comme un mini projet à dérouler en cycle en V. Il a des phases et des étapes, des porteurs et des contributeurs, des livrables en entrée et en sortie, des ressources allouées, un planning à respecter.
Notre prochain article portera sur la phase de Conception de l’exercice cyber (thématique, objectifs, format de l’exercice etc.)